로지스틱 회귀(Logistic Regression)는 분류 문제에 사용되는 지도 학습 알고리즘 중 하나입니다. 이름은 회귀라는 용어를 포함하고 있지만, 실제로는 분류를 수행합니다. 이 알고리즘은 이진 분류와 다중 클래스 분류 모두에 적용될 수 있습니다.
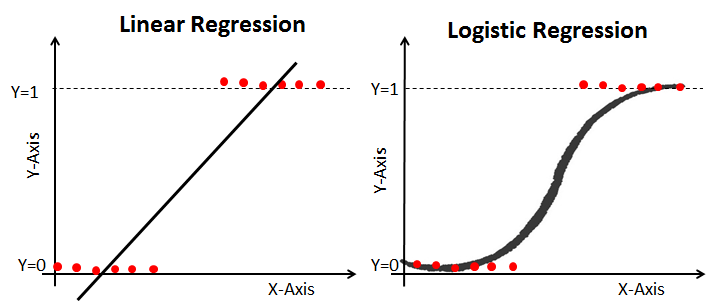
알고리즘 동작 방식:
- 로지스틱 함수: 로지스틱 회귀는 입력 특성의 선형 조합을 계산하고, 그 결과를 로지스틱 함수(또는 시그모이드 함수)에 적용합니다. 이 함수는 입력 값을 0과 1 사이의 값으로 변환합니다.
- 모델 학습: 학습 데이터를 사용하여 모델을 학습시킵니다. 이 과정에서는 최적의 가중치(계수)를 찾는 것이 목표입니다.
- 결정 경계: 학습된 모델은 입력 특성의 선형 조합을 계산하고, 그 결과를 로지스틱 함수에 적용하여 확률 값을 계산합니다. 확률 값은 입력 데이터가 특정 클래스에 속할 확률을 나타냅니다.
- 클래스 예측: 확률 값이 0.5보다 크면 해당 클래스로 예측하고, 그렇지 않으면 다른 클래스로 예측합니다. 이진 분류의 경우, 확률 값이 0.5보다 크면 긍정 클래스로 예측하고, 그렇지 않으면 부정 클래스로 예측합니다.
주요 특징:
- 선형 결정 경계: 로지스틱 회귀는 선형 결정 경계를 생성합니다. 즉, 입력 특성 공간을 두 영역으로 나누는 직선, 평면 또는 초평면을 찾습니다.
- 이진 및 다중 클래스 분류: 로지스틱 회귀는 이진 분류와 다중 클래스 분류 모두에 적용될 수 있습니다. 이진 분류의 경우 시그모이드 함수를 사용하고, 다중 클래스 분류의 경우 소프트맥스 함수를 사용합니다.
- 확률 기반 접근: 로지스틱 회귀는 입력 데이터가 특정 클래스에 속할 확률을 직접 추정합니다. 이를 통해 클래스의 불확실성을 고려할 수 있습니다.
적용 분야:
- 이메일 스팸 분류: 이메일이 스팸인지 아닌지를 분류할 때 로지스틱 회귀가 사용될 수 있습니다.
- 질병 진단: 환자의 의료 기록을 기반으로 질병을 진단하는데에도 로지스틱 회귀가 사용될 수 있습니다.
모델링
# 1단계: 불러오기
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, classification_report
# 2단계: 선언하기
model = LogisticRegression()
# 3단계: 학습하기
model.fit(x_train, y_train)
# 4단계: 예측하기
y_pred = model.predict(x_test)
# 5단계 평가하기
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
임계값 조정
# 예측값
y_pred[10:20]
# 예측 확률
p = model.predict_proba(x_test)
# 1로 분류될 확률값 확인
p1 = p[:, [1]]
p1[10:20]# 임계값: 0.5
y_pred2 = [1 if x > 0.5 else 0 for x in p1]
print(classification_report(y_test, y_pred2))
로지스틱 회귀는 강력하고 해석하기 쉬운 분류 알고리즘으로, 이진 분류와 다중 클래스 분류에 모두 사용될 수 있습니다. 확률 기반 접근을 통해 클래스 예측의 불확실성을 고려할 수 있습니다.
'PYTHON > 머신러닝' 카테고리의 다른 글
| [PYTHON] 앙상블(Ensemble) (0) | 2024.04.28 |
|---|---|
| [PYTHON] 그리드 탐색(Grid Search) (0) | 2024.04.28 |
| [PYTHON] 의사 결정 트리(Decision Tree) (0) | 2024.04.28 |
| [PYTHON] KNN K-최근접 이웃(K-Nearest Neighbors) (1) | 2024.04.28 |
| [PYTHON] 선형회귀 LinearRegression (0) | 2024.04.28 |


